Chapter 4 Fitness for use
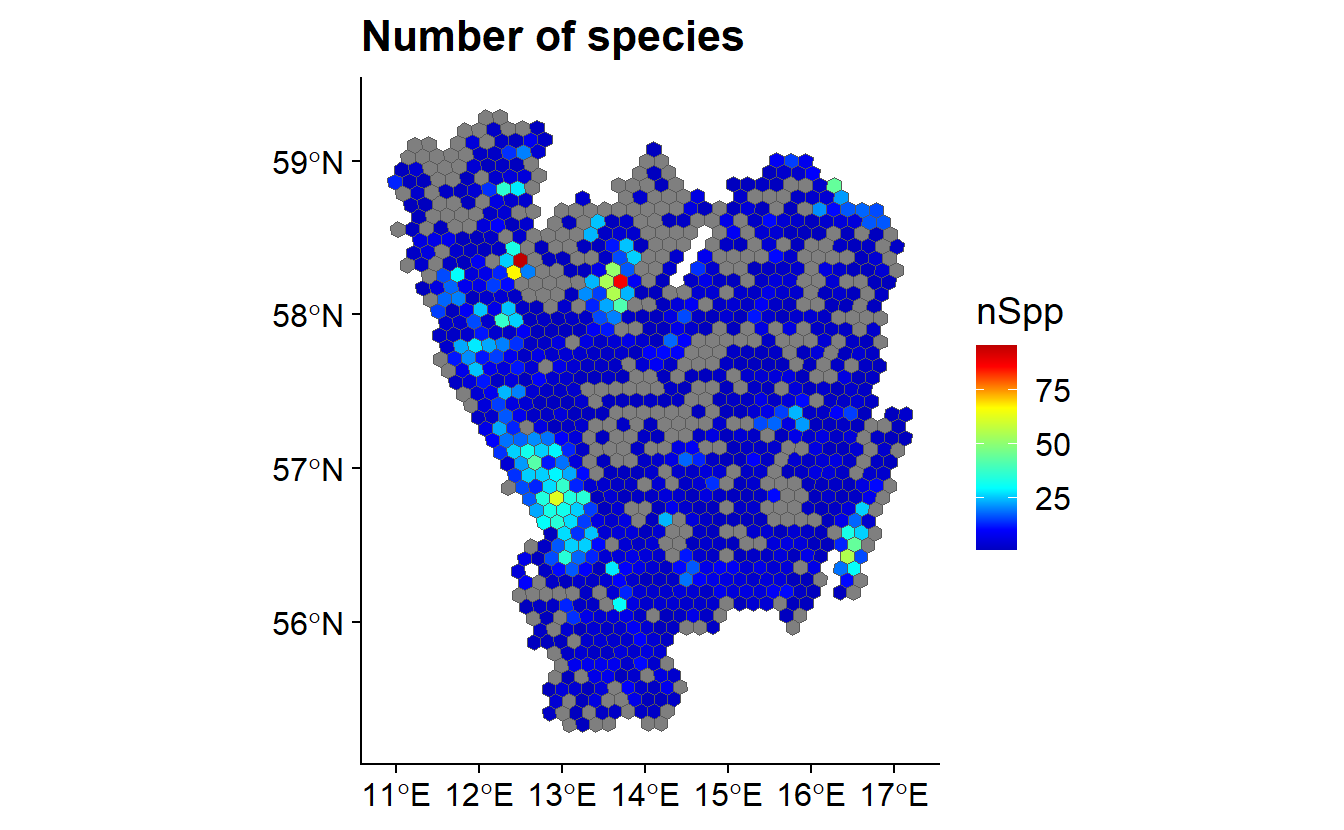
Knowledge of the quality of data available is very important. Quantifying gaps in data taxonomic, temporal and spatial is an important step. The R package BIRDS provides a resource to do all of these things. It can:
- Summarise spatial distribution of records;
- Summarise the temporal distribution of records; and
- Thorugh the implementation of ignorance scores, summarise likely gaps in biodiversity knowledge.
library(BIRDS)
data("bryophytaObs")
data("gotaland")
OB <- organiseBirds(bryophytaObs)
grid <- makeGrid(gotaland, gridSize = 10)
SB <- summariseBirds(OB, grid)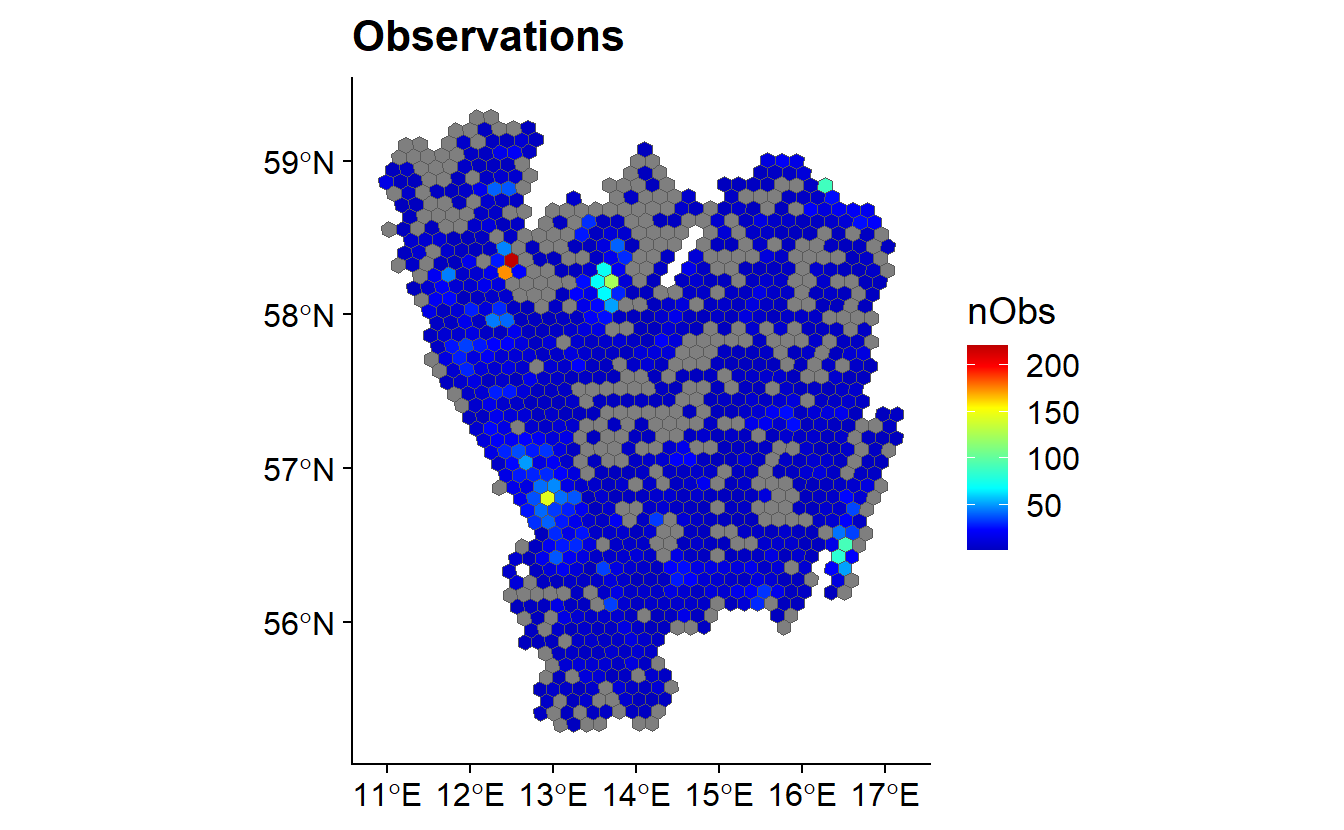
4.1 Bias
All data sets are biased to some degree. For field data, the structure of data gathering should be robust enough to reduce the effects of bias to a minimum. Data downloaded from biodiversity databases are by their nature from different sources. Such sources may have differing causes of bias and it is important to consider if and how such biases will affect research.
Sources of bias may include:
- accessibility of the landscape;
- human population density;
- distribution of expertise;
- “Charisma” of the taxa;
There is a large body of literature on different methods which may be employed. One of the simplest is the selection of background points with the same spatial bias as taxa which are searched for in the manner (Phillips et al. 2009). Such a layer can be produced using 2-dimensional kernel estimation through the MASS package
library(raster)
library(MASS)
data("bryophytaObs")
Sample_bias_layer <- raster( MASS::kde2d(
x = bryophytaObs$decimalLongitude,
y = bryophytaObs$decimalLatitude,
h = c(100,200),
lims = c(10,20,55,60)))More complex methods of accounting for bias can be created by more explicitly modeling accessibility or the behavior of recorders themselves. There are resources for doing this, including:
- recorderMetrics - Data derived metrics of recorder behavior (August et al. 2020)
- Sampbias - Bayesian analysis to quantify the effects of accessibility on species occurrence sets (Zizka, Antonelli, and Silvestro 2020)
Spatial sorting or dissaggregating presence points can reduce the effects of bias:
- ENMeval - Provides methods for quickly spatially aggregating presence points for model building;
- spThin - Randomly thins the number of presences used for a model by an agreed distance.